Tema 3 Fundamentos de Business Intelligence
Objetivos del tema 3
Con este tema se pretende capacitar para:
- Conocer los problemas de gestionar datos en un entorno tradicional y cómo se resuelven mediante la administración de bases de datos.
- Conocer los principios de diseño de bases de datos.
- Conocer los requisitos en la empresa para administrar los datos.
- Entender los desafíos e implicaciones del Big Data.
En este tema vamos a repasar algunos aspectos relacionados con el diseño y las herramientas necesarias en un sistema de información para que sirva de apoyo a la estrategia, la toma de decisiones y la gestión.
3.1 Introducción al Business Intelligence
3.1.1 La digitalización de las empresas y administraciones públicas en España
Según el informe “¿Cómo evoluciona la transformación digital en España?” que publicó el Ministerio de Asuntos Económicos y Transformación Digital en febrero de 2022: el 62 % de las pymes españolas tienen al menos un nivel básico de intensidad digital y el 24% ha abrazado el e-commerce, pero son pocas las empresas que aprovechan tecnologías como la inteligencia artificial, los macrodatos o los servicios en la nube. Es decir, las empresas y administraciones públicas españolas continúan avanzando en su camino hacia la digitalización.
La digitalización de una empresa no solo es una decisión sobre informática. Es más bien algo que afecta a la estrategia, la estructura, los procesos de trabajo, la forma de usar la tecnología, la selección y promoción de las personas y, en general, la cultura de la empresa.
En este contexto de digitalización, se hace evidente que los datos toman un papel cada vez más relevante en las empresas. Lo analizaremos con más detalle a continuación.
3.1.2 La empresa y los datos. Organizaciones data driven
En un contexto de empresas cada vez más digitalizadas, toman especial relevancia los datos.
Hoy en día confluyen tres factores:
El aumento exponencial de la generación de datos. Los datos se recogen ahora dentro y fuera de la empresa, se producen en un flujo continuo, proceden de múltiples fuentes (redes sociales, sensores, teléfonos móviles, clics en la web…) y formatos (imagen, documentos…). En consecuencia, ocupan una magnitud inmensa.
Mejor capacidad de almacenamiento, transmisión y procesamiento de datos, porque existen soluciones tecnológicas que lo permiten.
Reducción de su coste unitario.
Los factores anteriores suponen el comienzo de una nueva era, la “era de los datos”. Elisa Martín Garijo, Directora de Innovación y Tecnología, IBM España, opina que tienen un potencial de cambio en la sociedad similar al del petróleo o la electricidad en la era industrial, y que los datos son la nueva materia prima de esta era.
Este mayor volumen de información supone dificultades para las empresas:
Para que puedan explotar la información, es fundamental que sean capaces de rescatar aquella que sirva a los fines del negocio, la almacenen y la gestionen.
Escasez de perfiles tecnológicos y con habilidades para explotar los datos.
La velocidad a la que se generan los datos supera por mucho la capacidad de las empresas para asimilarla. Y, cuanto más se desarrolla la tecnología, más datos se generan.
A modo de ejemplo, en un minuto en el mundo: los usuarios de TikTok visualizaron 167 millones de videos, se producen 5,7 millones de búsquedas en Google, se gastan $283.000 en Amazon.
 Julio de 2022. Telefónica.](images/chapter31.png)
Figura 3.1: ¿Qué pasa en un minuto en Internet en 2021? Julio de 2022. Telefónica.
Sin embargo, también conlleva oportunidades para las empresas. Entre otras:
Optimización de procesos y aumento de la competitividad.
Mejora de la experiencia de usuarios.
Innovación en los productos y servicios ofrecidos.
Toma de mejores decisiones, si la información se procesa, analiza y gestiona adecuadamente.
Cabe mencionar el concepto de organizaciones data driven. Una compañía data driven es aquella que ha adaptado su cultura empresarial a un entorno digitalizado y que utiliza los datos para mejorar su funcionamiento.
Tienen las siguientes características: - Implantación de una política de analítica de datos muy estructurada, que incluye el uso de herramientas de análisis para el control de las principales KPIs.
Uso de herramientas de tecnología punta para tratar la información.
La comunicación entre la dirección de la empresa y los trabajadores es directa.
Posibilidad de tomar decisiones rápidas y óptimas.
La evaluación de los trabajadores se hace mediante un sistema que tiene en cuenta los objetivos cumplidos.
Es decir, son organizaciones que tratan de aprovechar al máximo el potencial de los datos.
3.1.3 ¿Qué es el Business Intelligence? Toma de decisiones con datos
Cuando hablamos del potencial de los datos, vemos que consiste en organizarlos, explotarlos y obtener conclusiones provechosas para la organización. El Business Intelligence contribuye en esta tarea.
El término Business Intelligence (BI por sus siglas en inglés) hace referencia al uso de estrategias y herramientas que sirven para transformar información en conocimiento, con el objetivo último de mejorar el proceso de toma de decisiones en una empresa y, en definitiva, el rendimiento de la empresa.
Para aplicar el BI, se deben seguir una serie de pasos:
- Comprender los datos. Hay que saber identificar la información que resulte efectiva para la toma de decisiones. Será aquella que cumpla tres requisitos:
Información precisa: implica que los datos que proporciona sean de calidad, exactos, claros.
Información oportuna: implica que la información llegue en el momento en el que se necesite, no más tarde, cuando ya no nos ayuda, ni antes de que sea necesaria, para no sobrecargar al usuario.
Información relevante: implica que la información sea importante para la toma de decisiones. Por ejemplo, puede no ser necesario saber todo el historial de compras de un cliente en un determinado momento, sino simplemente saber si ha probado o no antes un determinado producto.
Estas condiciones pueden parecer obvias, pero en muchos casos son difíciles de cumplir. Por ejemplo, puede suceder que los datos estén mal organizados, sean poco accesibles, con acceso lento, con errores… En gran medida, es el sistema de organización de datos el que condiciona la utilidad del sistema.
Seleccionar los datos que nos resulten útiles y en los que vayamos a basar la toma de decisiones. Lo que en marketing puede ser accesorio, en desarrollo de producto puede llegar a ser trascendental, por ejemplo.
Sacar conclusiones y analizar la estrategia actual y futura.
Por último, cabe mencionar que, en la práctica, el BI se traduce en herramientas que se alimentan de datos de negocio (de varias fuentes) y los transforman en informes, paneles, tablas y gráficos que sean fáciles de interpretar para el usuario.
3.2 Organización de datos en un entorno tradicional
3.2.1 El sistema de información tradicional
En las bases de datos tradicionales, los datos suelen estar almacenados en bases de datos o archivos y tienen una estructura tabular (tablas). La gestión de los datos se basa en tenerlos recopilados y disponibles para las aplicaciones.
Por ejemplo, podemos tener registros en un archivo de la contabilidad que recoge la información relativa a las facturas de venta y compra con todos sus datos, otros registros diferente en un archivo de recursos humanos, con una ficha para cada empleado cubriendo toda su información, otro archivo para los horarios, en los que de nuevo aparecen los datos de todas las personas en la empresa, etc.
Todos estos archivos pueden estar almacenados además en el mismo formato en una única base de datos o en tipos de archivos diferentes asociados a distintas clases de software (por ejemplo, una aplicación de contabilidad, un excel para los horarios, un CRM para los clientes…).
En las bases de datos tradicionales, la gestión de datos se basa en tener los datos disponibles por cada aplicación necesaria.
Por ejemplo, podemos tener registros en un archivo de la contabilidad que recoge la información relativa a las facturas de venta y compra con todos sus datos, otros registros diferente en un archivo de recursos humanos, con una ficha para cada empleado cubriendo toda su información, otro archivo para los horarios, en los que de nuevo aparecen los datos de todas las personas en la empresa, etc.
Todos estos archivos pueden estar almacenados además en el mismo formato en una única base de datos o en tipos de archivos diferentes asociados a distintas clases de software (por ejemplo, una aplicación de contabilidad, un excel para los horarios, un CRM para los clientes…).
3.2.2 Carencias de los sistemas de información tradicionales
Sin embargo, este sistema de gestión de archivos presenta cinco carencias muy importantes que limitan en gran medida la eficacia del sistema:
Redundancia de datos, datos duplicados: Por ejemplo, una misma persona aparecerá en el fichero de clientes y en el de pedidos también. Esto aumenta innecesariamente el volumen de información que es necesario almacenar.
Inconsistencia de datos: si los datos están duplicados en distintas ubicaciones, es posible que haya diferencias en la información que contiene. Por ejemplo, si un cliente aparece con distintos nombres en el fichero de clientes y en el de pedidos, ¿cuál es el correcto?
Dependencia del software: A veces los distintos programas específicos para cada función no son compatibles entre sí o no permiten el cambio a otro software sin perder la información o tener que volver a introducirla manualmente, lo que limita las opciones a la hora de cambiar de proveedor.
Falta de posibilidades de intercambio: Como no tenemos los datos integrados no podemos combinar información de distintas fuentes. Por ejemplo, no podemos combinar el historial de pedidos de un cliente con los horarios de los comerciales para ver con qué comercial ese cliente realiza más pedidos.
Mayores dificultades para la seguridad del sistema: es necesario establecer sistemas de seguridad y backup independiente para cada uno de los sistemas de archivo.
Las carencias anteriores se superan con un enfoque de BD relacional.
3.3 El enfoque de base de datos relacional
3.3.1 Enfoque relacional
Las bases de datos relacionales son un tipo específico de base de datos que pretende superar las limitaciones de los sistemas de organización de archivos tradicionales.
El enfoque de base de datos relacional es tan frecuente que a veces se utiliza indistintamente cuando se mencionan los Sistemas de Gestión de Bases de Datos (“Database Management Systems”) para referirse a una:
Colección de datos organizados para dar servicio a múltiples aplicaciones de manera eficiente al centralizar los datos y controlar los que son redundantes.
Así, citando a Laudon (2014) un Sistemas de Gestión de Base de Datos (DBMS) es el:
Software que permite a una organización centralizar los datos, administrarlos de manera eficiente y proveer acceso a los datos almacenados mediante programas de aplicación.
El enfoque de base de datos relacional se basa en la idea de separar la organización interna de los datos de las vistas lógicas que necesitan los usuarios, de forma que los datos se organicen de la forma más eficiente y, al mismo tiempo, se puedan personalizar las vistas según las necesidades de los usuarios.
Así, en este enfoque se trata de que:
- Cada dato se introduzca una sola vez en la base de datos y se almacene en un solo lugar.
- Las vistas se puedan personalizar y adaptar a distintas situaciones y usuarios.
3.3.2 Elementos básicos de una BD relacional
Una BD relacional está formada por varios elementos básicos: tablas, entidades y atributos, registros, claves y relaciones.
Partimos de que una BD tendrá dimensiones o variables qué se consideran el eje central de la información. Por ejemplo, una base de datos de clientes sitúa a los clientes como el centro de la información. Estas dimensiones se conocen con el nombre de “Entidad”.
En una BD relacional, se utiliza una “Tabla” distinta para cada entidad. Por ejemplo, una base de datos podría tener:
- Tabla de clientes
- Tabla de proveedores
- Tabla de pedidos
- Tabla de facturas
- Tabla de productos…
Cada tabla, contiene los datos de todas las entidades (por ejemplo, todos los clientes) y todos sus atributos o características (por ejemplo, nombre de la empresa, dirección, NIF, sector, número de empleados…)
Cuando la información de una entidad se incluye en la tabla de otra entidad, ambas tablas se pueden combinar en una sola. Por ejemplo, los pedidos que ha hecho un determinado cliente (tabla de pedidos) junto con las características de ese cliente (tabla de clientes). A esto se le llama “Crear una vista de la información”.
Esa conexión entre tablas se llama “Relación”. Para poder combinar estas tablas, es necesario:
- que los registros en cada una de ellas tengan indentificadores únicos, las denominadas “claves primarias”
- que los registros en una tabla incorporen la información para ligarlos a otra tabla con las denominadas “claves externas”, porque sirven para asociar información de una tabla externa con una determinada tabla.
Por ejemplo, podemos incorporar la clave primaria del cliente que ha hecho un pedido en la tabla de pedidos para poder combinar esa información.
Las claves primarias identifican inequívocamente cada registro “tupla” de una tabla. Las claves externas (también llamadas claves foráneas) sirven para indicar cómo un registro de una tabla se relaciona con registros de otras tablas.
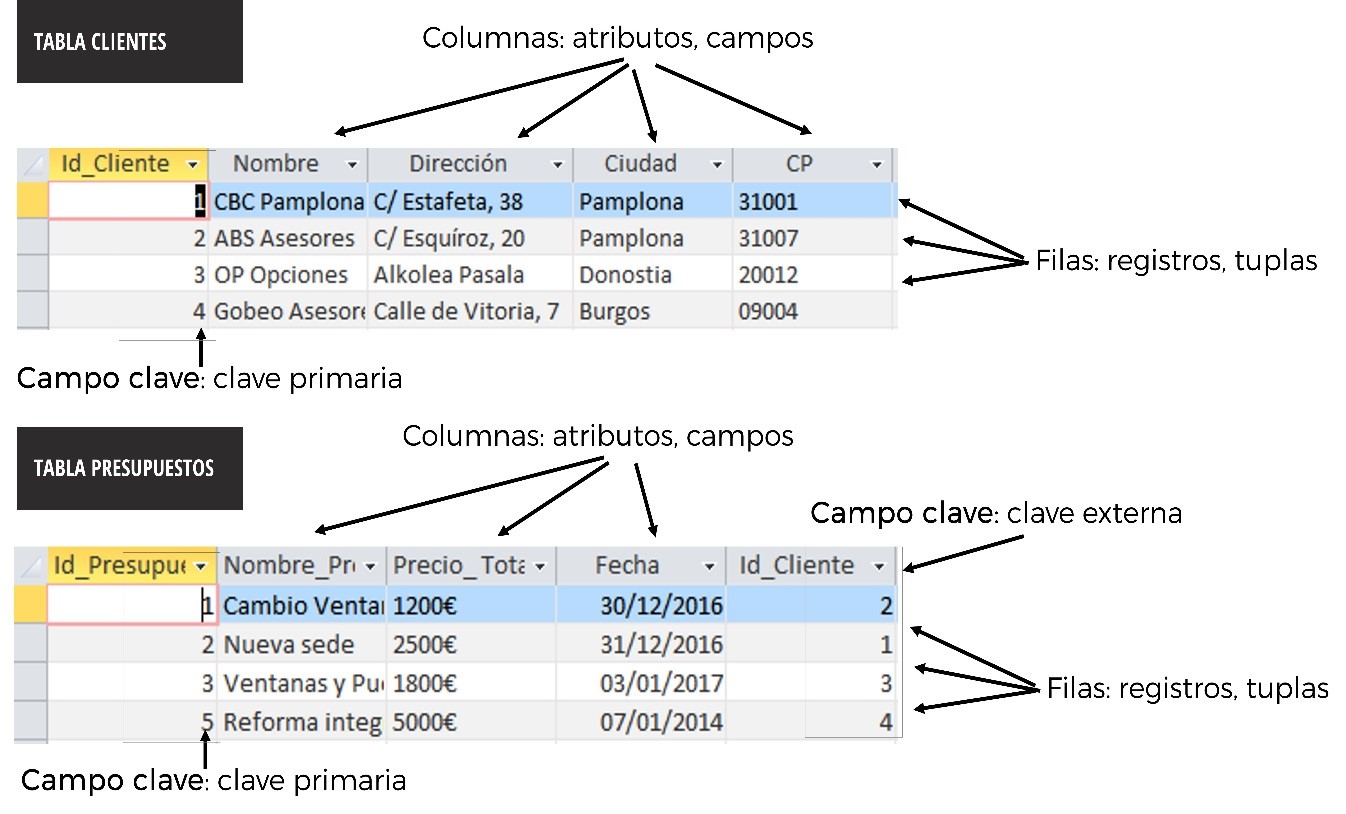
Figura 3.2: Elaboración propia
Por otro lado, cabe mencionar el concepto de ”Jerarquía”. Es una manera de organizar los elementos que integran una entidad, cuando estos están vinculados entre sí en una relación padre-hijo. Una jerarquía tiene forma de árbol.
Por ejemplo, si tenemos una tabla para la entidad ciudad, podremos ordenarlas por países y continentes.
Resumiendo, en una base de datos relacional tenemos los siguientes elementos:
| Representación lógica | Representación física | Modelo relacional |
|---|---|---|
| Tabla | Archivo secuencial | Relación |
| Fila | Registro | Tupla |
| Columna | Campo | Atributo |
Las claves primarias identifican inequívocamente cada registro “tupla” de una tabla. Las claves externas (también llamadas claves foráneas) sirven para indicar cómo un registro de una tabla se relaciona con registros de otras tablas.
Por último, hablaremos del “Esquema en estrella” de las BD relacionales.
Es el enfoque que habitualmente se adopta en las BD relacionales. Consiste en clasificar las tablas de la BD en tablas de “dimensiones” o tablas de “hechos”:
Las tablas de dimensiones describen las entidades. Por ejemplo, la tabla de clientes es una tabla de dimensiones que incluye la clave primaria de cada cliente y sus atributos. Cada cliente está presente una única vez en esta tabla. Normalmente responden estas preguntas: Qué, quién, cómo, cuándo, dónde…
Las tablas de hechos almacenan eventos e incluye columnas con las claves foráneas de más de una dimensión. Por ejemplo, la tabla de datos de pedidos recogerá todos los pedidos que ha hecho cada cliente y cada cliente puede aparecer más de una vez).
Las relaciones siempre se crean desde las tablas de dimensiones hacia las tablas de hechos (1:N). Las tablas de dimensiones nunca se relacionan entre sí.
Así pues, este sistema permite centralizar la introducción de información porque se introduce una sola vez cada dato, administrar estos datos (crear, modificar y borrar datos) de manera más eficiente.
Además, los sistemas DBMS actúan como interfaz entre aplicaciones y archivos de datos físicos: cuando una aplicación necesita un dato el DBMS lo busca en la base y lo proporciona.
En este sentido, en estos sistemas se separan las vistas lógicas y físicas de los datos y se resuelven los problemas de control de redundancias e inconsistencias, permitiendo además la gestión centralizada y la mayor seguridad.
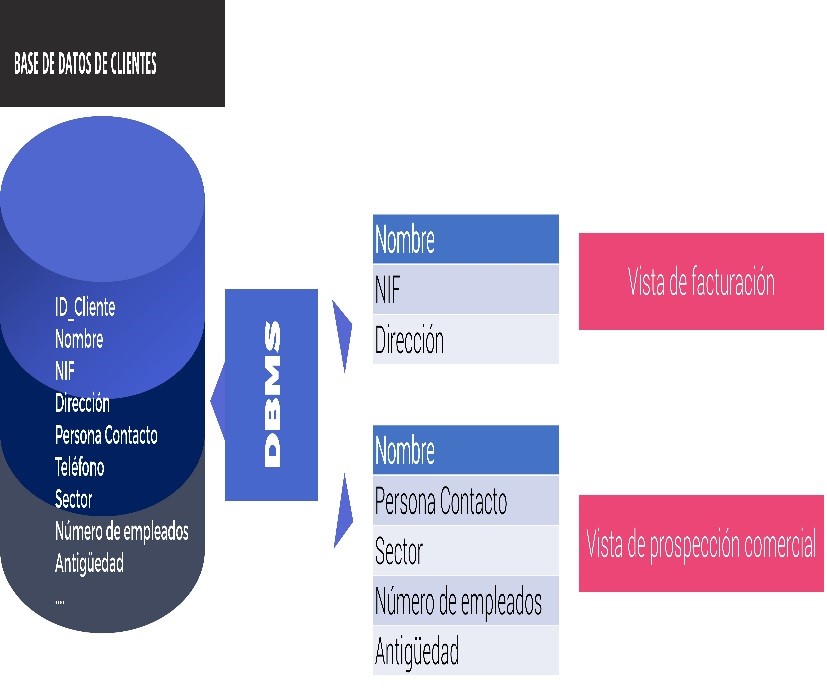
Figura 3.3: Elaboración propia
3.3.3 El proceso de diseño de bases de datos relacionales
El proceso de diseño de una base de datos relacional incluye:
Diseño conceptual (lógico): modelo abstracto, desde una perspectiva de perspectiva de negocio. Se trata de pensar bien qué datos son necesarios mantener desde el punto de vista del negocio, qué lógica de relaciones tienen, cómo deben presentarse…
Diseño físico: configuración de acceso en los distintos dispositivos. Se trata de decidir cómo va a estar organizada la información en tablas, cómo se va a almacenar, desde qué aplicaciones o dispositivos va a ser necesario acceder a ella..
Proceso de diseño: identifica relaciones entre datos y datos redundantes. Se decide cuál es la forma más eficiente agrupar elementos para satisfacer los requerimientos del negocio, necesidades de aplicación de los programas. Incluye las dos perspectivas anteriores.
En ese proceso de diseño, se realiza lo que se denomina “normalización”:
Normalización: Es la racionalización de agrupaciones complejas de datos para minimizar los elementos de datos redundantes y difíciles por su volumen.
Antes de transformar los datos o “dividirlos” en estructuras más pequeñas, debemos decidir qué reglas vamos a seguir en la transformación. Se denominan reglas de identidad referencial:
Comprobar que las relaciones entre tablas siguen reglas de coherencia: Por ejemplo, cuando una tabla tiene una clave foránea (externa) que apunta a otra, no es posible añadir un registro con una clave que no exista en la otra tabla
Diagrama entidad-relación: Utilizado por programadores para documentación, muestra las relaciones entre entidades: Los cuadros representan las entidades (sobre las que creamos cada uno de los archivos-tablas) y las líneas representan las relaciones. Suelen presentarse en rombos las relaciones y entre círculos los campos.
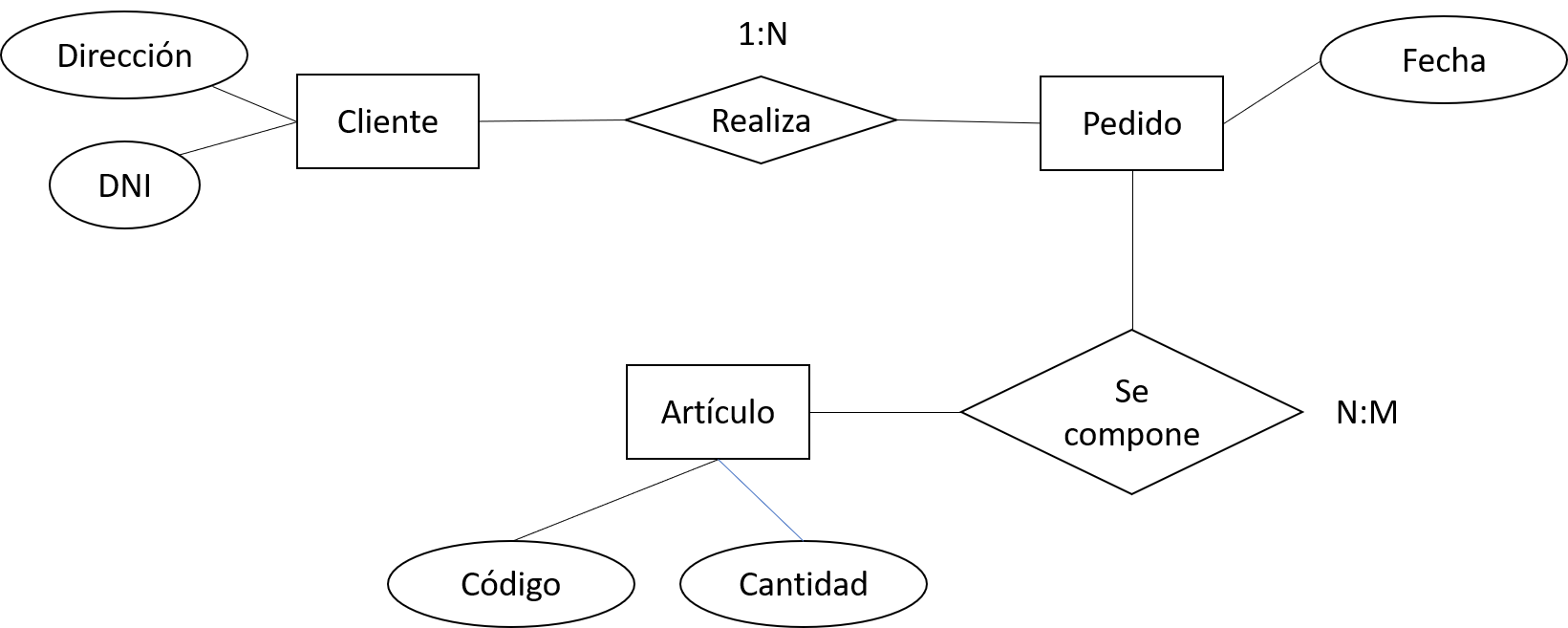
Figura 3.4: Ejemplo diagrama entidad relación
Por lo tanto, el diseño de una base de datos implica:
Definición de datos: Qué estructura específica tiene, cómo se crean las tablas y qué características tienen los campos (numéricos, de texto…), cómo se definen las claves internas y externas.
Creación del diccionario o diccionarios de datos: Ficheros manuales o automatizados que incluyen las definiciones de almacenamiento de los elementos y sus características. Es imprescindible crear estos diccionarios para poder consultarlos frecuentemente.
3.3.4 Gestión de bases de datos relacionales
Una vez que tenemos una definición teórica de la base de datos tenemos que decidir sobre qué hardware y software se implementa la base de datos e implementarla.
Selección del lenguaje de programación para el trabajo con la base de datos: añadir, cambiar, borrar, recuperar datos de la base de datos. El lengaje más extendido para el trabajo con bases de datos relacionales se denomina lenguaje de consulta estructurado o más habitualmente Structured Query Language (SQL). Este lenguaje está incorporado en muchas herramientas diferentes desde herramientas muy potentes a otras más básicas como, por ejemplo, Microsoft Access.
Selección de la herramientas de generación de informes y las vistas y consultas prediseñadas: se puede utilizar una misma herramienta para la generación de informes (por ejemplo, consultas SQL) o herramientas específicas. Por ejemplo, Crystal Reports es una aplicación para diseñar y generar informes desde fuentes de datos distintas.
3.3.5 Otros tipos de bases de datos
Aunque las bases de datos relacionales son las más habituales, podemos encontrarnos otros tipos de bases de datos:
Bases de datos jerárquicas o de red: En este tipo de bases, se almacena la información en una estructura jerárquica que enlaza los registros en forma de estructura de árbol, en donde un nodo padre de información puede tener varios nodos hijo, y así sucesivamente.
Bases de datos orientadas a objetos: Estas bases de datos surgen por la dificultad de incorporar en una base de datos tradicional componentes cada vez más frecuentes como las imágenes, vídeos, voz y otros elementos multimedia. Las bases de datos orientadas a objetos son más flexibles y tratan a cada entidades como un objeto completo y pueden integrar datos de orígenes distintos. Por contra, también son, en general, más lentas y menos eficientes que las relacionales, por lo que, cuando se pueden usar bases relacionales, suele ser más eficaz usar estas.
3.4 Business Intelligence
3.4.1 ¿Qué es el Business Intelligence? Toma de decisiones con datos
Como se ha comentado anteriormente, el término Business Intelligence hace referencia al uso de estrategias y herramientas que sirven para transformar información en conocimiento, con el objetivo último de mejorar el proceso de toma de decisiones en una empresa y, en definitiva, el rendimiento de la empresa.
En concreto, los denominados sistemas de Business Intelligence son sistemas de apoyo a la toma de decisiones. Utilizan la información generada en los distintos sistemas de procesamiento de transacciones para analizarla de forma centralizada y poder generar insights que faciliten la toma de decisiones.
3.4.2 Los sistemas de información (ETL, Data Warehouse, Datamart, directorio de información, capa de análisis)
El siguiente esquema muestra la composición de las herramientas de Business Intelligence. Se dividen en tres elementos: la capa de integración, el almacén de datos y la capa de análisis.
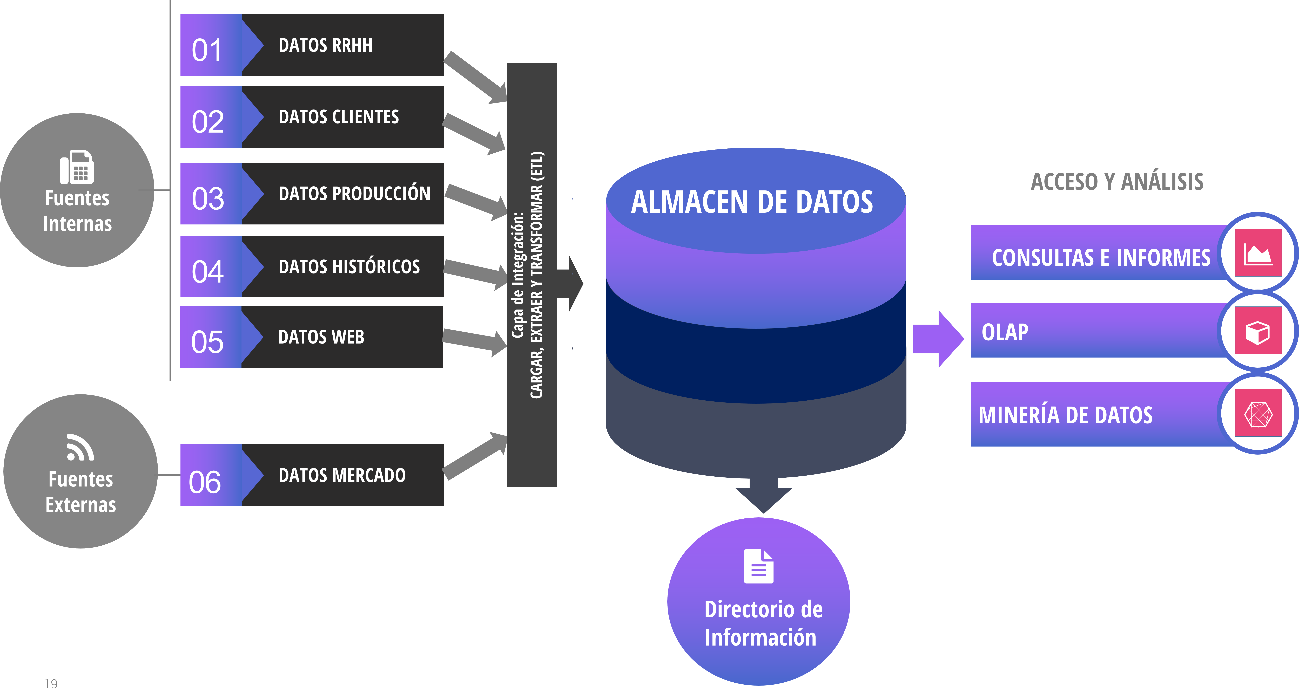
Figura 3.5: Elementos en un sistema de Business Intelligence
La herramienta se alimenta con información input de distintas fuentes, tanto internas como externas a la organización. Esta información tiene distintos formatos y características, por lo que no se puede cargar directamente en la herramienta, sino que hay que transformarla antes. De esto se encarga la denominada capa ETL o capa de integración, que Extrae, Transforma y carga (Load) los datos al almacén central.
El almacén de datos (también denominado Data Warehouse) centraliza todos los datos actuales e históricos de los distintos sistemas y bases de datos de la organización y también los que provienen de fuentes externas. Es equivalente a una base de datos central, diseñada para poder realizar informes y análisis que combinan la información de todas estas fuentes. Su función es organizarlos de tal manera que la información de todas estas fuentes esté relacionada entre sí. Este DataWarehouse a veces se separa en Datamarts que son subconjuntos del almacén de datos para propósitos específicos.
El almacén de datos cuenta con un directorio de información. Es el catálogo que permite a los usuarios conocer qué datos hay disponibles en el almacén y entenderlos.
El último de los elementos que componen las herramientas de BI es el de acceso y análisis a la información. Es la capa front-end de la herramienta. Ofrece al usuario herramientas que le permiten interactuar con los datos, crear dashboards e informes, supervisar KPI, extraer y analizar datos, y más. Profundizaremos en los distintos tipos de análisis de datos en el apartado siguiente.
Adicionalmente a los elementos anteriores, la documentación de una herramienta es especialmente importante. Suele dividirse en dos informaciones; la documentación técnica y la documentación de negocio.
La documentación técnica informa sobre cómo está configurado el sistema y cómo se ha programado exactamente. Su destinatario es un usuario con conocimientos de informática. Permite que nuevos desarrolladores entiendan el funcionamiento de la herramienta y puedan modificarla.
La documentación de negocio informa sobre dos cuestiones: las necesidades de la empresa a las que responde la herramienta; y las razones por las qué se ha estructurado la herramienta de una manera u otra. Su destinatario no tendrá necesariamente conocimientos de informática, sino una necesidad de negocio que pretende resolver con la herramienta.
3.4.3 Herramientas de análisis de datos (SQL, reporting, OLAP, minería de datos)
Con respecto al capa de acceso y análisis a la información de los sistemas de BI, se pueden realizar muchos tipos de análisis distintos a partir de los datos del datawarehouse o de los data marts.
Los principales análisis suelen ser de los siguientes tipos:
- Consultas a la base de datos: consiste en enviar a la base de datos una petición de información. El usuario deberá especificar qué requisitos tiene que cumplir esa información. La herramienta consultará una o varias tablas de la base de datos y le mostrará la información que ha solicitado.
Por ejemplo, si queremos conocer el DNI de los clientes a los que les vendimos algún producto el año pasado, deberemos enviar esta petición de información: consultar la tabla clientes, filtrar el año (2022) y recuperar solo los DNIs de los clientes. Existen muchas opciones de software para hacer consultas a las BD, y en cada software la consulta tiene que escribirse en un “lenguaje” específico. El lenguaje de consulta más utilizado es SQL (Structured Query Language).
Las consultas de SQL se estructuran en las órdenes o “comandos”. Los más comunes son:
SELECT – Obtener datos de la base de datos. Es uno de los comandos más populares, ya que todas las peticiones comienzan con una consulta SELECT.
FROM – Especifica la tabla o tablas desde la que se obtienen los datos.
WHERE – Filtra los datos para que cumpla una serie de condiciones.
AND – Permite añadir condiciones.
ORDER BY – Ordenar los resultados de los datos numérica o alfabéticamente.
SUM – Resume los datos de una columna concreta y los muestra en forma de suma.
UPDATE – Modificar las filas existentes en una tabla.
INSERT – Añadir nuevos datos o filas a una tabla existente.
Siguiendo con nuestro ejemplo, escribiríamos esta consulta:
SELECT DNI
FROM Tabla_Clientes
WHERE AÑO=2022- Informes y cuadros de mando: son paneles en los que se incluyen representaciones gráficas de aquellos datos que el usuario considera influyentes en su análisis.
Los informes y los cuadros de mando (dashboard) son elementos diferentes:
En ambos casos sirven para analizar los datos y en ambos casos muestran gráficos, tablas, mapas, tarjetas y otros objetos visuales. Son diferentes en su finalidad: los informes suelen disponer de varias páginas con componentes interactivos variados, para lograr una rica experiencia analítica en modo autoservicio. Los informes se pueden editar y adaptar al análisis. Los cuadros de mando o paneles, por su parte, nos sirven para recibir una información más resumida y específica (conclusiones rápidas). Se nutren de páginas de informes.
Una forma habitual de presentar los datos en los informes y cuadros de mando es en forma de KPIs. Las siglas KPI provienen de los términos en inglés Key Performance Indicators, cuya traducción al español es “indicadores clave de rendimiento”.
Los KPIs son las variables, factores y unidades clave que permiten medir el desempeño de una empresa u organización, con el fin de saber si se está cumpliendo los objetivos establecidos.
Para que un KPI funcione como debe, este tiene que cumplir con algunas características. Debe ser:
Alcanzable: Los objetivos planteados deben de ser realistas.
Medible: Aunque suene obvio, un KPI debe de poder medirse.
Relevante: Muestra solo los más importantes, los que son clave.
Periódico: El indicador tiene que ser analizable periódicamente.
Exacto: Elige solo la parte más precisa de toda la información recabada.
Análisis Multidimensional (OLAP): El Análisis Multidimensional es un tipo especial de informe que permite visualización de datos de múltiples dimensiones, permite respuestas rápidas en línea y consultas ad-hoc.
Se pueden combinar varias dimensiones de análisis para contestar por ejemplo, cuestiones como ¿cuántas unidades del producto X se venden en el mercado Y en el mes de junio en comparación con el mercado Z?
- Minería de datos: Por último, minería de datos es un término muy general para referirse a los análisis que pueden realizarse combinando la información en el almacén de datos, lo que también se menciona frecuentemente como herramientas de ciencia de datos. Estas herramientas de minería de datos incluyen análisis econométricos como regresiones múltiples, análisis cluster, series temporales y análisis multidimensionales y también otras técnicas de Machine Learning e Inteligencia Artificial que se mencionan en el siguiente apartado.
3.4.4 Tipos de análisis de datos: descriptivo, de diagnóstico, predictivo y prescriptivo
Existen distintos tipos de análisis de datos:
Descriptivo: Analiza los datos pasados y presentes para comprender la evolución de la empresa en diferentes hitos temporales. Da respuesta a la pregunta: “¿Qué ha ocurrido?”
Diagnóstico: Analiza por qué se está desarrollando una tendencia o se ha producido un problema, y permite a la empresa abordarlos. Da respuesta a la pregunta: “¿Por qué ha ocurrido?”
Predictivo: Utiliza estadísticas y técnicas de modelado de datos para predecir los resultados futuros de la empresa. Permite reducir el riesgo de los acontecimientos futuros. Da respuesta a la pregunta: “¿Qué es probable que ocurra en el futuro?”
Prescriptivo: Analiza posibles escenarios, los recursos disponibles, el rendimiento pasado/actual y sugiere una estrategia. Da respuesta a la pregunta: ¿Cuál es la mejor estrategia a seguir?”
3.5 Storytelling con datos
3.5.1 El data storytelling
Una de las principales herramientas de análisis de datos son los informes y cuadros de mando. Para que los informes sean útiles para el usuario, no es suficiente con que los datos se representen gráficamente. Los datos tienen que contar una historia que permita al usuario extraer conclusiones que le aporten valor.
En este contexto nace el concepto de data storytelling. Consiste en realizar un análisis de datos y comunicar la información resultante a través de una historia.
En el año 2016, Chris Haleua de Adobe y Eduard Latour de Lego, presentaron un gráfico que resume la idea del storytelling con datos. Según su teoría, se compone de tres elementos que combinados dan como resultado una comunicación efectiva. Son: los datos, la visualización y la narrativa.
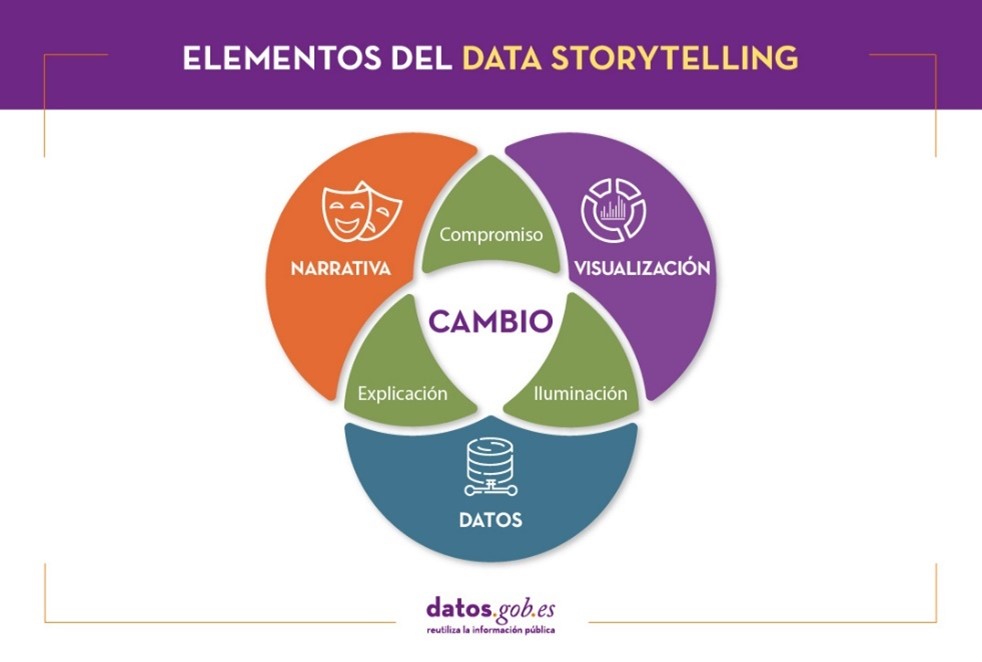
Figura 3.6: Elementos del data storytelling. Haleua y Latour (2016)
Al combinar los datos y la narrativa, nos movemos en el terreno de la explicación o contexto de la historia. Gracias al contexto, la audiencia comprende qué ocurre (o va a ocurrir) y por qué es importante.
Al combinar los elementos visuales con los datos, sucede la “iluminación”. Los conocimientos se muestran de una forma llamativa y fácil de comprender, permitiendo observar relaciones y patrones.
Al combinar la narrativa y los elementos visuales, se conecta con la audiencia captando su atención y generando un compromiso.
Cuando se combinan los tres elementos se logra una historia basada en datos que puede influir e impulsar el cambio en la audiencia.
3.5.2 Construcción de la historia
Hay que seguir varios pasos:
- Definir la audiencia
¿Quién va a escuchar o ver la historia? ¿Qué motiva a esta persona? ¿Cuáles son sus preocupaciones y problemas? En concreto, en un ambiente empresarial: ¿cuáles son los objetivos y los resultados que espera? ¿cuáles son sus verdaderas preocupaciones?
Para conocer a la audiencia, habrá que emplear marcos de trabajo como el perfilado de usuario, el design thinking, el mapa de empatía que nos pueden ayudar a entender mejor al destinatario de la historia.
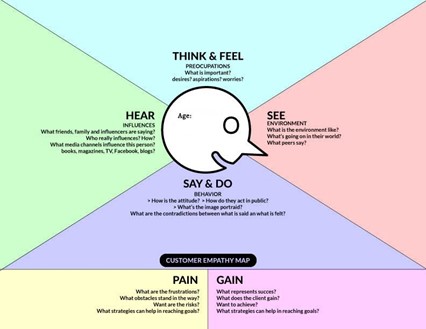
Figura 3.7: Mapa de empatía del consumidor
- Recopilar información
Consiste en reunir toda la información y datos relacionados con el tema que se va a analizar. El objetivo es hacer “brainstroming” y recopilar todo el conocimiento que nos pueda servir en el análisis.
- Determinar el mensaje principal que se quiere trasmitir
Entre toda la información recopilada, hay que buscar el hecho más importante e impactante, el que va a ser el mensaje principal de nuestra historia.Preguntémonos… si la audiencia va a llevarse una sola frase o mensaje de lo que va a ver, leer o analizar… ¿cuál es?
- Crear la estructura narrativa de la historia
Consiste en definir la estructura y el sentido del mensaje que vamos a transmitir, de manera que tenga un orden lógico. Por regla general, las historias se estructuran en tres partes: principio, desarrollo o nudo y final. Durante la historia explicaremos los mensajes principales que hemos determinado en el punto anterior y les daremos énfasis.
El hecho de que la historia siga un orden lógico tiene que ver con la forma en que los seres humanos procesamos y recordamos la información. El objetivo de esta estructura es que, cuando termine, la audiencia tome una decisión o realice una acción concreta.
- Elabora la herramienta de comunicación Finalmente, hay preparar la herramienta mediante la cual la audiencia va a recibir el mensaje. Puede ser una presentación, una infografía, un dashboard en una herramienta visual como PowerBI, un artículo, u otros.
3.5.3 Mejores prácticas en la visualización de datos
A la hora de crear informes o cuadros de mando y representar datos gráficamente, debemos tener en cuenta buenas prácticas y consejos que hacen que nuestras visualizaciones sean más eficaces.
Una visualización de datos será excelente cuanto cumpla estos dos requisitos:
- Responda al propósito para el que se ha creado el objeto visual.
- Permita comprender los datos que está representando.
Para conseguirlo, hay que tener en cuenta dos cuestiones:
- Elegir el tipo de gráfico adecuado
Tendencias en el tiempo: las mejores visualizaciones para mostrar tendencias en el tiempo son los gráficos de líneas, de área y de barras. Se debe intentar asignar el tiempo al eje de las X y el valor al eje de las Y. Esto permitirá que la vista se adecue a nuestras convenciones culturales respecto del análisis de tendencias.
Comparación y clasificación: las mejores visualizaciones para la comparación y clasificación son los gráficos de barras. Estos gráficos codifican valores cuantitativos en sentido longitudinal y sobre la misma línea de base, lo que facilita la comparación de valores.
Correlación: la correlación consiste en descubrir relaciones entre dos medidas. Las mejores visualizaciones para la correlación son los diagramas de dispersión.
Distribución: muestra la manera en que los valores cuantitativos que se están exhibiendo se distribuyen en todo su rango cuantitativo. Las mejores visualizaciones para mostrar la distribución son el diagrama de cajas y el histograma.
Parte de un todo: normalmente se emplean gráficos circulares para realizar un análisis de “las partes del todo”. Sin embargo, es preferible evitarlos por dos motivos:
- El sistema visual humano no tiene mucha capacidad para calcular el área; y
- Solo se pueden comparar áreas que se encuentren una junto a otra. En cambio, los gráficos de barras muestran estas distribuciones de manera más clara.
- Datos geográficos: las mejores visualizaciones para mostrar datos geográficos son los mapas. Los mapas dan un mejor resultado cuando se combinan con gráficos en los que se detalla lo que se muestra en ellos (por ejemplo, un gráfico de barras o incluso con una matriz que muestra datos reales).
- Crear vistas eficaces
Para crear vistas eficaces, las representaciones de datos tienen que cumplir varias reglas:
Enfatizar los datos más importantes, para que el usuario no se pierda en el gráfico y saque en claro las conclusiones que se pretende mostrarle.
Evitar sobrecargar las vistas e incluir demasiada información en un gráfico.
Hacer los gráficos más legibles. Por ejemplo, si incluimos etiquetas en los gráficos, resulta más fácil leerlas si su orientación es horizontal y no vertical.
3.6 Big Data e Inteligencia Artificial
3.6.1 El Big Data
Se denomina Big Data al conjunto masivo de datos no estructurados o semi-estructurados de tráfico de Web, social media, sensores, etc… En general, entendemos por “grande” aquel lo que cumple las denominadas 3Vs del Big Data: Volumen, Variedad y Velocidad.
El volumen se refiere a la cantidad de datos. En la siguiente imagen podemos ver la equivalencia de las distintas medidas de tamaño en datos. Cuando hablamos de Big Data, estamos hablando de unidades de medida en Petabytes, es decir, un millón de gigabytes.
- bit: Es la unidad mínima de información que puede almacenar un sistema informático: vale 0 o 1
- Byte: conjunto de 8 bits, puede representar todos los caracteres del código ASCII en un código hexadecimal.
- Con Big Data nos referimos a la unidad de medida Petabyte (1.000.000 gigabytes).
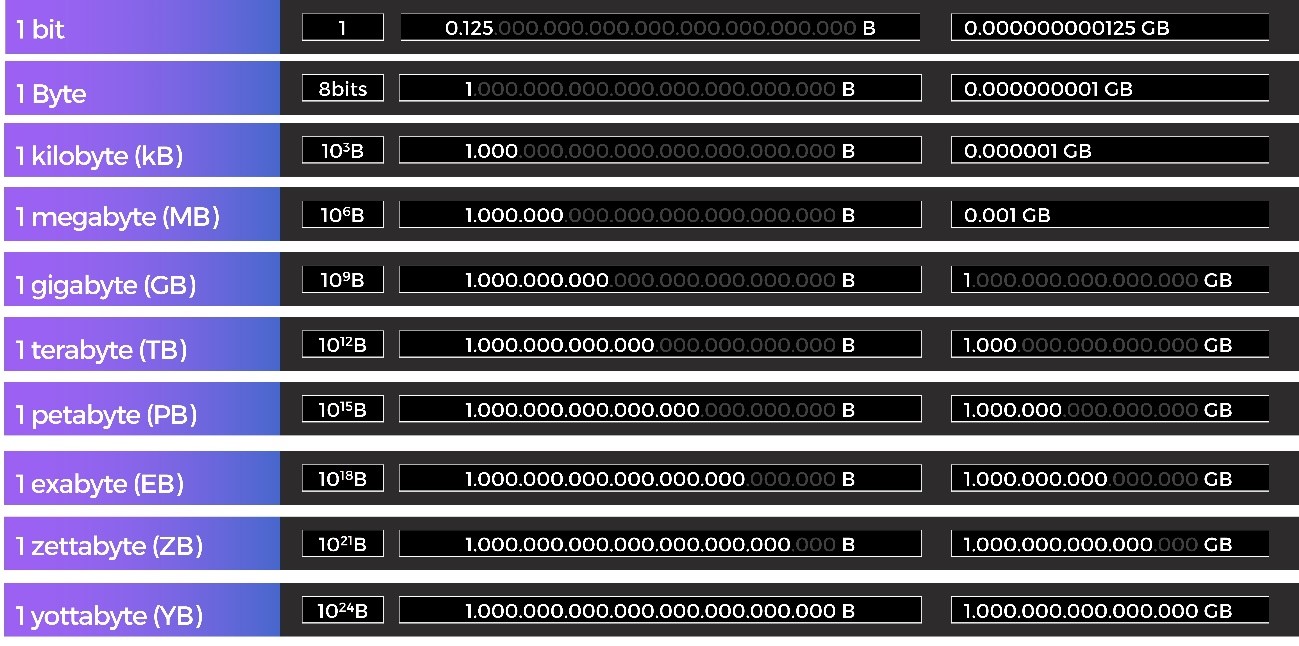
Figura 3.8: Unidades de medidas de datos
Con respecto a la variedad, como ya hemos mencionado al hablar de bases de datos relacionales, denominamos datos no estructurados a los elementos multimedia como videos, fotos, registros de los dispositivos del Internet of Things…. Estos datos de origen variado son difíciles de acomodar en las bases de datos y los análisis estadísticos y econométricos tradicionales.
Hoy en día existen tecnologías capaces de almacenar datos de estas características:

Figura 3.9: Diferencias entre Data Warehouse y Data Lake
Por otro lado, la velocidad se refiere a que gran parte de estos datos se están generando en tiempo real, como toda la información del IoT y la información en redes sociales y esta información necesita así mismo analizarse en tiempo real para la que la información que proporciona sea útil.
Por último, podemos considerarla la Veracidad la cuarta V del Big Data. Se refiere a que, al recoger tantos datos de diferentes fuentes, puede peligrar la exactitud y la coherencia de los datos.
3.6.2 Inteligencia Artificial
El término genérico Inteligencia Artificial se refiere simplemente a la capacidad de una máquina para aprender como respuesta a los estímulos y acomodar su comportamiento a ese aprendizaje.

Figura 3.10: Ejemplos:Caras ficticias creadas por GANs
Entre las aplicaciones empresariales de la inteligencia artificial encontramos aplicaciones como:
- Selección de recursos humanos
- Predicción de riesgo de abandono de clientes
- Predicción de la probabilidad de compra
- Clasificación del email…
Entre las herramientas más importantes para trabajar con inteligencia artificial y big data nos encontramos:
- Lenguajes de programación: Python y R con RStudio
- Plataformas distribuidas: Apache Spark, Apache Hadoop
- Plataformas de trabajo: Jupyter, Anaconda
- Algoritmos de libre uso: BERT y otros, OpenAI
El Machine Learning (aprendizaje automático) es una rama de la inteligencia artificial que permite que las máquinas aprendan sin ser expresamente programadas para ello.
Se trata de sistemas capaces de identificar patrones en los datos y, a partir del conocimiento que han adquirido, deducir cuál es el resultado óptimo para un determinado problema.
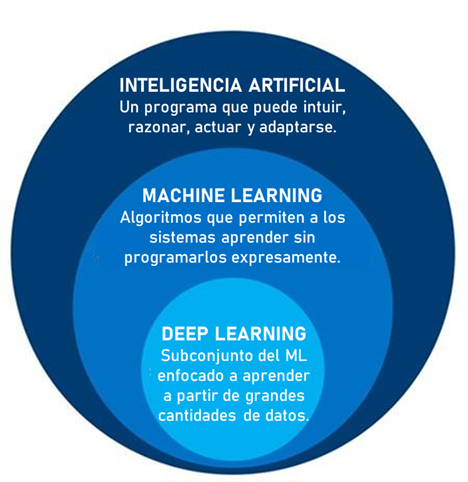
Figura 3.11: Elaboración propia
3.6.3 El Internet de las Cosas
El término Internet de las Cosas (IoT) se refiere a objetos físicos (“cosas”) que llevan incorporados sensores, software y otras tecnologías con el fin de conectarse e intercambiar datos con otros dispositivos y sistemas a través de Internet.
Ejemplos:
Iluminación inteligente. Bombillas que se conectan y se pueden controlar a través de dispositivos (cambiar color, intensidad, etc.).
Amazon Go. Cajeros inteligentes que identifican, a través de su chip, los productos que ha adquirido un cliente.
3.6.4 Las ciudades Inteligentes
Una Ciudad Inteligente (Smart City) es aquella que utiliza el potencial de la tecnología para promover:
El desarrollo sostenible de la ciudad.
Una mayor eficacia de los recursos disponibles.
Una mejor calidad de vida de sus ciudadanos.
Ejemplos:
Gestión inteligente de residuos. Utilización de sensores inteligentes que midan el sistema de llenado de los contendedores y planifiquen rutas de recogida de residuos eficientes.
Teleasistencia domiciliaria. Se trata de hacer un seguimiento de los signos vitales de pacientes con movilidad reducida. Los centros médicos reciben la información en tiempo real y pueden tomar decisiones en base a ella (enviar una ambulancia, hacer una video llamada, etc.).
Bibliografía recomendada para el tema 3
- Laudon, K. y Laudon, J.P. 2014. Sistemas de Información Gerencial, 14ed. Pearson. Capítulo 6
- Heredero de Pablos Heredero, Carmen; López Hermoso Agius,José Joaquín; Martín-Romo Romero, Santiago; Medina Salgado, Sonia. 2019. Organización y transformación de los sistemas de información en la empresa, ESIC Capítulo 3.
- Kroenke, D.M. and Boyle, R.J. 2017. Experiencing MIS, Pearson. Capítulo 5.
- Rainer, R. K. y Prince, B. 2018. Introduction to Information Systems. Wiley. Capítulo 3, Capítulo 5.
- Valacich, J. Schneider, C. 2018. Information Systems Today, 8th ed. Pearson, Capítulo 6.